tansformer 从入门到上手只需要看这一篇
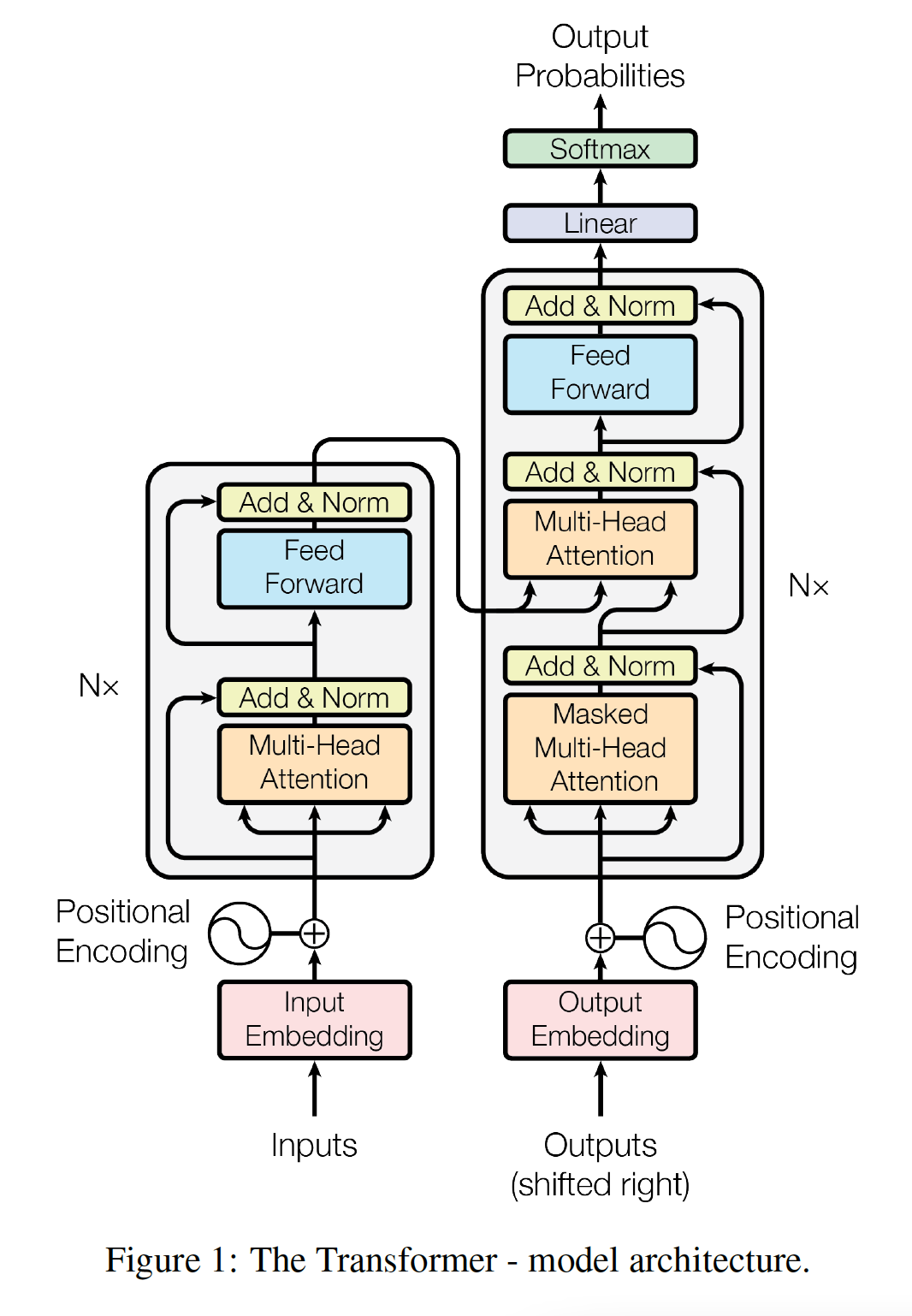
架构总览
词嵌入层 Embeddings
输入 token 的索引处在维度为词表大小 d_vocab 的空间里,每个 token 要经过词嵌入层变成维度为 d_model 的特征向量。
1 2 3 4 5 6 7 8 class Embeddings (nn.Module): def __init__ (self, d_model, d_vocab ): super (Embeddings, self ).__init__() self .lut = nn.Embedding(vocab, d_model) self .d_model = d_model def forward (self, x ): return self .lut(x) * math.sqrt(self .d_model)
在原论文,编码器输入、解码器输入以及解码器输出是使用相同参数的 Embeddings,但是在有些地方,发现解码器输出是使用单独的生成器 Generator 结构,原因是因为解码器输出在功能上是获取一个从特征向量到词表空间的概率映射。
1 2 3 4 5 6 7 8 9 class Generator (nn.Module): "Define standard linear + softmax generation step." def __init__ (self, d_model, d_vocab ): super (Generator, self ).__init__() self .proj = nn.Linear(d_model, vocab) def forward (self, x ): return torch.log_softmax(self .proj(x), dim=-1 )
位置编码 Positional Encoding
为了让模型利用序列的次序,必须注入一些关于序列中的相对位置或绝对位置的信息。为此,在 encoder stack 和 decoder stack 底部的 input embedding 中添加了 positional encoding 。positional encoding 与 embedding 具有相同的维度 ,因此可以将二者相加。
P j = ( P E ( j , 1 ) , P E ( j , 2 ) . . . P E ( j , d m o d e l ) ) P E ( j , 2 i ) = sin ( j 10000 2 i / d m o d e l ) , P E ( j , 2 i + 1 ) = cos ( j 10000 2 i / d m o d e l ) P_j=(PE_{(j,1)}, PE_{(j,2)}...PE_{(j,d_{model})}) \\
PE_{(j,2i)}=\sin(\frac{j}{10000^{2i/d_{model}}}), PE_{(j,2i+1)}=\cos(\frac{j}{10000^{2i/d_{model}}})
P j = ( P E ( j , 1 ) , P E ( j , 2 ) ... P E ( j , d m o d e l ) ) P E ( j , 2 i ) = sin ( 1000 0 2 i / d m o d e l j ) , P E ( j , 2 i + 1 ) = cos ( 1000 0 2 i / d m o d e l j )
其中,j 表示 position,i 表示维度。即 positional encoding 的每个维度对应于一个正弦曲线,正弦曲线的波长从 2 π 2\pi 2 π i = 0 i=0 i = 0 10000 × 2 π 10000 \times 2\pi 10000 × 2 π 2 i = d m o d e l 2i=d_{model} 2 i = d m o d e l
对于任意固定的偏移量 k,P j + k P_{j+k} P j + k P j P_j P j
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 class PositionalEncoding (nn.Module): """实现Positional Encoding功能""" def __init__ (self, d_model, dropout=0.1 , max_len=5000 ): """ 位置编码器的初始化函数 :param d_model: 词向量的维度,与输入序列的特征维度相同,512 :param dropout: 置零比率 :param max_len: 句子最大长度,5000 """ assert d_model % 2 == 0 super (PositionalEncoding, self ).__init__() self .dropout = nn.Dropout(p=dropout) pe = torch.zeros(max_len, d_model) position = torch.arange(0 , max_len, dtype=torch.float ).unsqueeze(1 ) div_term = torch.exp( torch.arange(0 , d_model, 2 ).float () * (-math.log(10000.0 ) / d_model) ) pe[:, 0 ::2 ] = torch.sin( position * div_term ) pe[:, 1 ::2 ] = torch.cos( position * div_term ) pe = pe.unsqueeze(0 ) self .register_buffer("pe" , pe) def forward (self, x ):transformer1 """ x: [seq_len, batch_size, d_model] 经过词向量的输入 """ x = ( x + self .pe[:, : x.size(1 )].clone().detach() ) return self .dropout(x)
多头注意力
注意力机制 Scaled Dot-Product Attention
原论文叫 Scaled Dot-Product Attention (放缩点积注意力),架构如上图左侧所示。
注意力机制包括 Query ( Q ),Key ( K )和 Value ( V )三个组成部分,这三个部分由W Q , W K , W V W_Q,W_K,W_V W Q , W K , W V
Q ( l e n _ q , d _ k ) = X Q ( l e n _ q , d m o d e l ) ⋅ W Q ( d m o d e l , d _ k ) K ( l e n _ v , d _ k ) = X V ( l e n _ v , d m o d e l ) ⋅ W K ( d m o d e l , d _ k ) V ( l e n _ v , d _ v ) = X V ( l e n _ v , d m o d e l ) ⋅ W V ( d m o d e l , d _ v ) Q(len\_q, d\_k) = X_Q(len\_q, d_model) \cdot W_Q(d_model, d\_k) \\
K(len\_v, d\_k) = X_V(len\_v, d_model) \cdot W_K(d_model, d\_k) \\
V(len\_v, d\_v) = X_V(len\_v, d_model) \cdot W_V(d_model, d\_v)
Q ( l e n _ q , d _ k ) = X Q ( l e n _ q , d m o d e l ) ⋅ W Q ( d m o d e l , d _ k ) K ( l e n _ v , d _ k ) = X V ( l e n _ v , d m o d e l ) ⋅ W K ( d m o d e l , d _ k ) V ( l e n _ v , d _ v ) = X V ( l e n _ v , d m o d e l ) ⋅ W V ( d m o d e l , d _ v )
其中 Q 和 K 有相同的特征维度 d_k,而 K 和 V 有相同的长度维度 len_v,它们由X Q , X V X_Q,X_V X Q , X V X Q = X V X_Q=X_V X Q = X V
在很多代码中W Q , W K , W V W_Q,W_K,W_V W Q , W K , W V
注意力计算公式为:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Q ∈ R l e n q × d k , K ∈ R l e n v × d k , v ∈ R l e n v × d v , Q K T ∈ R l e n q × l e n v , A t t e n t i o n ( Q , K , V ) ∈ R l e n q × d v Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V \\
Q \in \R ^{len_q \times d_k},K \in \R ^{len_v \times d_k},v \in \R ^{len_v \times d_v}, QK^T \in \R ^{len_q \times len_v}, Attention(Q,K,V) \in \R ^{len_q \times d_v}
A tt e n t i o n ( Q , K , V ) = so f t ma x ( d k Q K T ) V Q ∈ R l e n q × d k , K ∈ R l e n v × d k , v ∈ R l e n v × d v , Q K T ∈ R l e n q × l e n v , A tt e n t i o n ( Q , K , V ) ∈ R l e n q × d v
内积注意力使用了 1 / d k 1/\sqrt{d_k} 1/ d k
因为输出特征维度为 d_v,所以为了添加残差,通常要求 d_v=d_model 或者也可以引入一个d v → d m o d e l d_v \to d_model d v → d m o d e l
多头注意力 Multi-Head Attention
多头注意力将 query, key, value 线性投影 h 次,其中每次线性投影都是不同的并且将 query, key, value 分别投影到 d k , d k , d v d_k,d_k,d_v d k , d k , d v d v d_v d v
原论文说,多头注意力允许模型在每个位置联合地关注来自不同子空间的信息。如果只有单个注意力头,那么平均操作会抑制这一点。
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , h e a d 2 . . . h e a d h ) W O h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) W i Q ∈ R d m o d e l × d k , W i K ∈ R d m o d e l × d k , W i V ∈ R d m o d e l × d v , W O ∈ R ( h d v ) × d m o d e l MultiHead(Q,K,V)=Concat(head_1,head_2 ... head_h)W^O \\
head_i=Attention(QW^Q_i,KW^K_i,VW^V_i) \\
W^Q_i \in \R ^{d_{model} \times d_k},W^K_i \in \R ^{d_{model} \times d_k},W^V_i \in \R ^{d_{model} \times d_v},W^O \in \R ^{(hd_v) \times d_{model}}
M u lt i He a d ( Q , K , V ) = C o n c a t ( h e a d 1 , h e a d 2 ... h e a d h ) W O h e a d i = A tt e n t i o n ( Q W i Q , K W i K , V W i V ) W i Q ∈ R d m o d e l × d k , W i K ∈ R d m o d e l × d k , W i V ∈ R d m o d e l × d v , W O ∈ R ( h d v ) × d m o d e l
公式中给出的是更一般的形式,实际上这里的输入 Q 对应上文注意力机制中的X Q X_Q X Q X V X_V X V d k = d v = d ∗ m o d e l / h = 64 d_k=d_v=d*{model}/h=64 d k = d v = d ∗ m o d e l / h = 64
在 Transformer 中以三种不同的方式使用多头注意力:
在 encoder-decoder attention 层中,query 来自于前一个 decoder layer,key 和 value 来自于 encoder 的输出。这允许 decoder 中的每个位置关注 input 序列中的所有位置。这模仿了 sequence-to-sequence 模型中典型的 encoder-decoder attention 注意力机制。
encoder 包含自注意力层。在自注意力层中,所有的 query, key, value 都来自于同一个地方(在这个 case 中,就是 encoder 中前一层的输出)。encoder 中的每个位置都可以关注 encoder 上一层中的所有位置。
类似地,decoder 中的自注意力层允许 decoder 中的每个位置关注 decoder 中截至到当前为止(包含当前位置)的所有位置。我们需要防止 decoder 中的信息向左流动,从而保持自回归特性。我们通过在 scaled dot-product attention 内部屏蔽掉 softmax input 的某些 value 来实现这一点(将这些 value 设置为 -1e9,一个很小的数),这些 value 对应于无效连接 illegal connection。
代码实现 pytorch
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 def clones (module, N ): "Produce N identical layers." return nn.ModuleList([copy.deepcopy(module) for _ in range (N)]) def attention (query, key, value, mask=None , dropout=None ): ''' query: (len_q, d_k) key: (len_v, d_k) value: (len_v, d_v) mask: (len_q, len_v) fill true ''' d_k = query.size(-1 ) scores = torch.matmul(query, key.transpose(-2 , -1 ))/math.sqrt(d_k) if mask is not None : scores = scores.masked_fill(mask, -1e9 ) p_attn = torch.softmax(scores, dim = -1 ) if dropout is not None : p_attn = dropout(p_attn) return torch.matmul(p_attn, value), p_attn class MultiHeadedAttention (nn.Module): def __init__ (self, h, d_model, dropout=0.1 ): ''' Take in model size and number of heads. We assume d_v always equals d_k. ''' super (MultiHeadedAttention, self ).__init__() assert d_model % h == 0 self .d_k = d_model // h self .h = h self .linears = clones(nn.Linear(d_model, d_model), 4 ) self .attn = None self .dropout = nn.Dropout(p=dropout) def forward (self, query, key, value, mask=None ): ''' query: (len_q, d_k) key: (len_v, d_k) value: (len_v, d_k) mask: (len_q, len_v) fill true ''' if mask is not None : mask = mask.unsqueeze(1 ) nbatches = query.size(0 ) query, key, value = [ lin(x).view(nbatches, -1 , self .h, self .d_k).transpose(1 , 2 ) for lin, x in zip (self .linears, (query, key, value)) ] x, self .attn = attention( query, key, value, mask=mask, dropout=self .dropout ) x = ( x.transpose(1 , 2 ) .contiguous() .view(nbatches, -1 , self .h * self .d_k) ) del query del key del value return self .linears[-1 ](x)
编码器掩码 length mask
注意力计算中 socre 的维度为(len_q, len_v),因为 torch.softmax(scores, dim = -1)计算最后一个维度列,对不同列之间进行 softmax,所以实际上是对每行数据 softmax。这样要保证每行不能全被 mask,防止计算出现 NaN。这样对 len_v 列维度进行 mask 就行了,len_q 对应部分最终计算 loss 时会被过滤掉,没有影响。
这里预期的输入 batch_mask (N, len) 是已经处理好的输入序列的掩码(True 代码填充部分),只需要在批次维度N和序列长度维度len之间填充一个维度,那么在 scores.masked_fill(mask, -1e9) 时,最后维度 len_v 的掩码会自动在前面维度 len_q 上广播,而不用考虑 len_q 的长度变化,这样这个掩码既可以在编码器计算自注意力时用到,又可以用在计算交叉注意力时。
1 2 3 4 5 6 def len_mask (batch_mask ) -> torch.Tensor: return batch_mask.clone().unsqueeze(-2 ) def len_mask2 (batch_mask, len_q ) -> torch.Tensor: return batch_mask.clone().unsqueeze(-2 ).expand(*batch_mask.shape, len_q).transpose(-1 , -2 )
解码器掩码 causal mask
我们给模型的完整输入为 ( x 1 , x 2 . . . x n ) (x_1, x_2...x_n) ( x 1 , x 2 ... x n ) x i x_i x i
1 2 3 4 5 6 7 def subsequent_mask (size ): "Mask out subsequent positions." attn_shape = (1 , size, size) subsequent_mask = torch.triu(torch.ones(attn_shape), diagonal=1 ).type ( torch.uint8 ) return subsequent_mask == 1
标准化
这里对末尾维度也就是特征维度进行标准化,标准化后还通过了一个线性层。
这里分别对线性层的权重初始化为 1,偏置初始化为 0。而 nn.liner 默认使用 Kaiming 初始化权重,均匀分布初始化偏置。
1 2 3 4 5 6 7 8 9 10 11 12 13 class LayerNorm (nn.Module): "Construct a layernorm module (See citation for details)." def __init__ (self, features, eps=1e-6 ): super (LayerNorm, self ).__init__() self .a_2 = nn.Parameter(torch.ones(features)) self .b_2 = nn.Parameter(torch.zeros(features)) self .eps = eps def forward (self, x ): mean = x.mean(-1 , keepdim=True ) std = x.std(-1 , keepdim=True ) return self .a_2 * (x - mean) / (std + self .eps) + self .b_2
残差连接 residual connections
这里对传入的子层标准化后添加残差。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class SublayerConnection (nn.Module): """ A residual connection followed by a layer norm. Note for code simplicity the norm is first as opposed to last. """ def __init__ (self, d_model, dropout ): super (SublayerConnection, self ).__init__() self .norm = LayerNorm(d_model) self .dropout = nn.Dropout(dropout) def forward (self, x, sublayer ): "Apply residual connection to any sublayer with the same size." return x + self .dropout(sublayer(self .norm(x)))
逐位置前馈网络 Position-wise Feed-Forward Networks
F F N ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x)=max(0, xW_1+b_1)W_2+b_2
FFN ( x ) = ma x ( 0 , x W 1 + b 1 ) W 2 + b 2
先将 x 从 d_model=512 维投影到 dff=2048 维,再投影回 d_model=512 维。
1 2 3 4 5 6 7 8 9 10 11 class PositionwiseFeedForward (nn.Module): "Implements FFN equation." def __init__ (self, d_model, d_ff, dropout=0.1 ): super (PositionwiseFeedForward, self ).__init__() self .w_1 = nn.Linear(d_model, d_ff) self .w_2 = nn.Linear(d_ff, d_model) self .dropout = nn.Dropout(dropout) def forward (self, x ): return self .w_2(self .dropout(self .w_1(x).relu()))
编码器 Ecoder
对于单个编码器,先通过残差连接包裹的 self_attn 自注意力层,再通过残差连接包裹的 feed_forward 逐位置前馈网络层。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class EncoderLayer (nn.Module): "Encoder is made up of self-attn and feed forward (defined below)" def __init__ (self, d_model, self_attn, feed_forward, dropout ): super (EncoderLayer, self ).__init__() self .self_attn = self_attn self .feed_forward = feed_forward self .sublayer = clones(SublayerConnection(d_model, dropout), 2 ) self .size = d_model def forward (self, x, mask ): "Follow Figure 1 (left) for connections." x = self .sublayer[0 ](x, lambda x: self .self_attn(x, x, x, mask)) return self .sublayer[1 ](x, self .feed_forward)
完整编码器就是把上面的编码重复 N 层,然后通过一个标准化层。
1 2 3 4 5 6 7 8 9 10 11 12 13 class Encoder (nn.Module): "Core encoder is a stack of N layers" def __init__ (self, layer, N ): super (Encoder, self ).__init__() self .layers = clones(layer, N) self .norm = LayerNorm(layer.size) def forward (self, x, mask ): "Pass the input (and mask) through each layer in turn." for layer in self .layers: x = layer(x, mask) return self .norm(x)
解码器 Decoder
单个解码器里有两个注意力层,第一个注意力层先对输出结果计算自注意力,再将结果输出到第二个注意力层与编码器的输出结果一起计算交叉注意力,随后进入一个逐位置前馈网络层,这三层都使用前面定义的残差连接包裹。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class DecoderLayer (nn.Module): "Decoder is made of self-attn, src-attn, and feed forward (defined below)" def __init__ (self, size, self_attn, src_attn, feed_forward, dropout ): super (DecoderLayer, self ).__init__() self .size = size self .self_attn = self_attn self .src_attn = src_attn self .feed_forward = feed_forward self .sublayer = clones(SublayerConnection(size, dropout), 3 ) def forward (self, x, memory, src_mask, tgt_mask ): "Follow Figure 1 (right) for connections." m = memory x = self .sublayer[0 ](x, lambda x: self .self_attn(x, x, x, tgt_mask)) x = self .sublayer[1 ](x, lambda x: self .src_attn(x, m, m, src_mask)) return self .sublayer[2 ](x, self .feed_forward)
完整解码器就是把上面的解码层重复 N 层,然后通过一个标准化层。
1 2 3 4 5 6 7 8 9 10 11 12 class Decoder (nn.Module): "Generic N layer decoder with masking." def __init__ (self, layer, N ): super (Decoder, self ).__init__() self .layers = clones(layer, N) self .norm = LayerNorm(layer.size) def forward (self, x, memory, src_mask, tgt_mask ): for layer in self .layers: x = layer(x, memory, src_mask, tgt_mask) return self .norm(x)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Transformer (nn.Module): """ A standard Transformer architecture. """ def __init__ ( self, src_vocab, tgt_vocab, N=6 , d_model=512 , d_ff=2048 , h=8 , dropout=0.1 ): super (Transformer, self ).__init__() c = copy.deepcopy attn = MultiHeadedAttention(h, d_model) ff = PositionwiseFeedForward(d_model, d_ff, dropout) position = PositionalEncoding(d_model, dropout) self .encoder = Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N) self .decoder = Decoder( DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N ) self .src_embed = nn.Sequential(Embeddings(d_model, src_vocab), c(position)) self .tgt_embed = nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)) self .generator = Generator(d_model, tgt_vocab) for p in self .parameters(): if p.dim() > 1 : nn.init.xavier_uniform_(p) def forward (self, src, tgt, src_mask, tgt_mask ): "Take in and process masked src and target sequences." out = self .decode(self .encode(src, src_mask), src_mask, tgt, tgt_mask) return self .generator(out) def encode (self, src, src_mask ): return self .encoder(self .src_embed(src), src_mask) def decode (self, memory, src_mask, tgt, tgt_mask ): return self .decoder(self .tgt_embed(tgt), memory, src_mask, tgt_mask)
测试
测试一下是否能跑通,测试没有问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 def inference_test (): test_model = Transformer(11 , 11 , 2 ) test_model.eval () src = torch.LongTensor([[1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 ]]) src_mask = torch.ones(1 , 1 , 10 ) src_mask = src_mask == 0 memory = test_model.encode(src, src_mask) ys = torch.zeros(1 , 1 ).type_as(src) for i in range (9 ): out = test_model.decode(memory, src_mask, ys, subsequent_mask(ys.size(1 ))) prob = test_model.generator(out[:, -1 ]) _, next_word = torch.max (prob, dim=1 ) next_word = next_word.data[0 ] ys = torch.cat( [ys, torch.empty(1 , 1 ).type_as(src.data).fill_(next_word)], dim=1 ) print ("Example Untrained Model Prediction:" , ys) def run_tests (): for _ in range (10 ): inference_test()
训练第一个模型
这里我在网上找到了阿里云的天池数据集打榜挑战赛,并选择了中文医疗信息处理评测基准 CBLUE 中的中文医学命名实体识别 V2(CMeEE-V2)任务。
下载数据
数据好像下载要申请,挺麻烦,我直接在 huggingface 上找到了相同数据集。
1 2 3 4 5 6 7 8 # 先配置 git lfs ,不然大文件不会克隆下来 conda install git-lfs git lfs install # 对于大于5G的huggingface数据,还需要 pip install huggingface_hub huggingface-cli lfs-enable-largefiles . # 克隆数据 git clone https://huggingface.co/datasets/Rosenberg/CMeEE-V2
训练
将之前的模型部分的代码整理到 transformer.py 文件中,然后导入里面的类和函数。
我设置 N=2, d_model=128, d_ff=512, batch_size=5 ,已经挺小的了,训练一个但是还是需要4个G的显存,以及每训练一个epoch需要2.9小时的时间。时间和本地电脑资源实在不太够用。
训练结果和代码已上传git:https://github.com/hs3434/CMeEE-V2
从loss来看,是随着训练下降的。